
Wie HyperFinity seine Serverless-Architektur mit Snowpark für Python von Snowflake optimiert
HyperFinity ist eine SaaS-Plattform für Entscheidungsfindungswissenschaft. Durch maschinelles Lernen und KI, integrierte Analysen und Datenvisualisierung ermöglicht HyperFinity nicht-technischen Benutzern datengesteuerte Entscheidungen zu treffen und einfache Ausgaben zu erstellen, die nachgelagerte Systeme wie CRM, ERP oder Content-Management-Systeme versorgen. Dies ermöglicht Unternehmen, ML-gestützte Entscheidungen schnell in mehreren Bereichen zu treffen, von einer intelligenteren Lieferkette bis hin zu optimierten Preisen.
Snowflake bildet den Kern der datenintensiven Plattform von HyperFinity. Neben der umfangreichen Unterstützung für Datentypen wie den Variant-Datentyp für semi-strukturierte Daten dienen andere Funktionen wie die Snowflake REST API und Zero-Copy Cloning als wertvolle Werkzeuge in der serverlosen Architektur der Plattform. Das Secure Data Sharing von Snowflake optimiert zudem die ELT-Prozesse und vereinfacht die Integration der HyperFinity-Plattform und ihrer Ausgaben mit unseren Kunden, die bereits Snowflake nutzen.
Herausforderung: Getrennte Infrastruktur für getrennte Programmiersprachen
Während die Plattform von HyperFinity für nicht-technische Benutzer entwickelt wurde, um maschinelles Lernen und KI auf Knopfdruck einfach anzuwenden, wird die gesamte Funktionalität für die benötigte Datenverarbeitung von einem datenwissenschaftlich orientierten Team entwickelt, dessen primäre Programmiersprachen SQL und Python sind. Snowflake kümmerte sich um unsere gesamte SQL-Entwicklung und -Verarbeitung, aber um eine serverlose Compute-Engine für unseren Python-Code zu konstruieren, musste unser Team einen neuen Satz an Cloud-Infrastruktur auf AWS einrichten, was die Verknüpfung mehrerer Compute-Dienste wie Amazon EC2 und AWS Lambda erforderte. Dies hatte mehrere Nachteile, wie z. B. das Verschieben von Daten aus dem Governance-Bereich von Snowflake zur Verarbeitung, die Wartung zusätzlicher Infrastruktur und das Schreiben von zusätzlichem Code zur Handhabung von sich ändernden Datenstrukturen zwischen den Diensten.
Als wir die Python-Unterstützung für Snowpark angekündigt sahen, waren wir sehr begeistert von den Möglichkeiten, die sich uns dadurch eröffneten, und wir hatten das große Glück, an der privaten Vorschau teilnehmen zu können.
Optimierung unserer Architektur mit Snowpark für Python
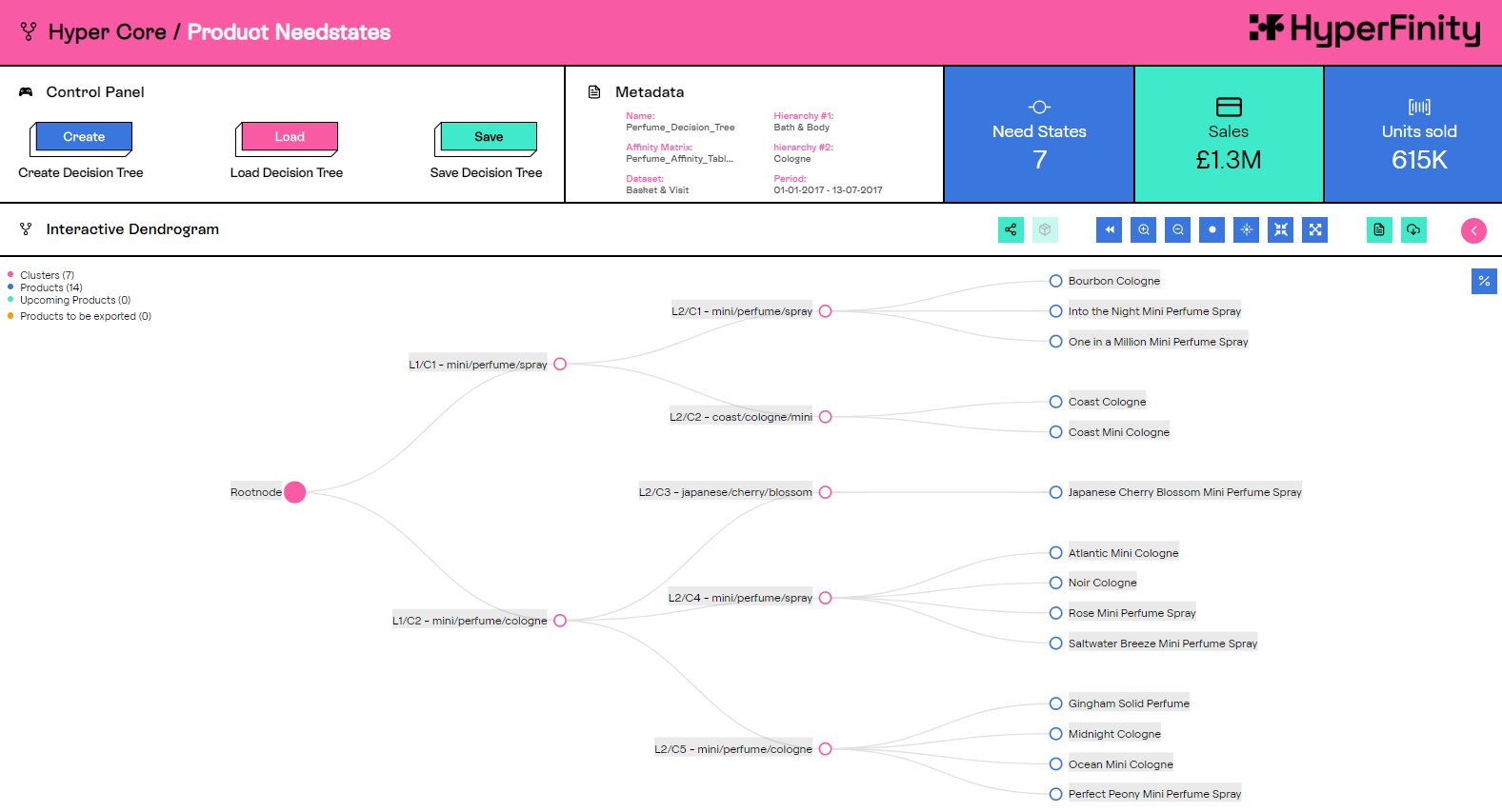
Einer der Vorteile von Python ist sein reiches Ökosystem an Open-Source-Paketen und Bibliotheken, die wir extensiv nutzen. Zum Beispiel ist ein Kernbestandteil der Plattform die Erstellung von „Customer Needstates“ für Produktgruppen. Hierbei wird eine Technik namens hierarchisches Clustering verwendet, um einen Kundenentscheidungsbaum zu erstellen, der die Entscheidungen eines Individuums darstellt, bis es das gekaufte Produkt erreicht. Die Berechnung dieser Needstates erfordert Matrix- und Array-Multiplikation, die unser Team in Snowpark mithilfe der Python-Bibliotheken numpy und scipy nutzt. Diese Art von Berechnung ist durch die Verwendung von Snowpark einfacher in Snowflake zu entwickeln und zu implementieren.
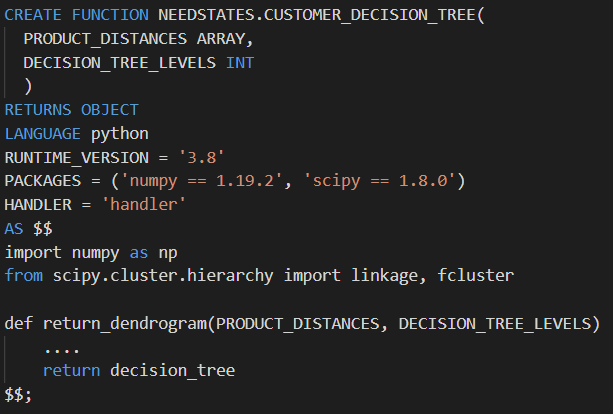
Frühere Cloud-Infrastruktur für Python-Verarbeitung ersetzt durch einfachen Snowpark-Code
Da die Snowpark für Python-Umgebung mit über 1.000 vorinstallierten Bibliotheken durch die Partnerschaft von Snowflake mit Anaconda geliefert wird, konnten wir bestehende Funktionen mit minimalem Aufwand verschieben. Die Verfügbarkeit der beliebtesten Bibliotheken entfernt eine weitere Verwaltungsebene aus dem Entwicklungsprozess, und mit dem integrierten conda-Paketmanager muss man sich keine Gedanken über die Abhängigkeitsverwaltung machen. Falls wir eine benutzerdefinierte Bibliothek benötigen, unterstützt Snowflake die Möglichkeit, benutzerdefinierten Python-Code hochzuladen und zu importieren.
Wir können auch SQL- und Python-Logik so miteinander kombinieren, dass dies zuvor das Hin- und Herschicken von Daten zwischen mehreren Tools bedeutet hätte, und unser Team konnte auch die Leistung durch Parallelisierung unserer Verarbeitung steigern. Durch die Verwendung dieser Kombination aus SQL und Python können wir in Python geschriebene Logik auf mehreren SQL-Zeilen gleichzeitig ausführen, wodurch eine bisher serielle Operation zu einem parallelen Prozess wird. Beispielsweise dauert die Ausführung unserer Clustering-Lösungen mit fünf verschiedenen Tiefen genauso lange wie die Ausführung mit einer Tiefe.
„Snowpark ermöglicht es uns, die Entwicklung zu beschleunigen und gleichzeitig die Kosten für Datenbewegungen und den Betrieb separater Umgebungen für SQL und Python zu senken.“
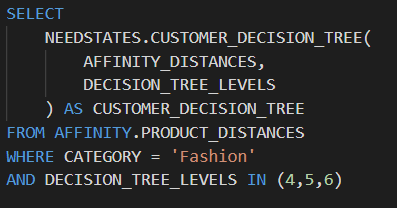
Ausführen einer Python-Funktion als Teil einer SQL-Anweisung in Snowflake, einschließlich paralleler Verarbeitung
Die Verlagerung unserer Python-Prozesse zu Snowpark hat unnötige Komplexität aus unserer Architektur entfernt und unsere Entwicklung vereinfacht, indem wir den gesamten zusätzlichen Code, der sich ändernde Datenstrukturen zwischen Diensten handhabte, eliminiert haben. Jetzt kann unser Team seinen Python-Code in derselben Umgebung entwickeln, testen und bereitstellen, in der die Daten gespeichert sind, und dabei die Leistung der Snowflake-Plattform und seine bevorzugte Entwicklungssprache nutzen.
HyperFinity ist eine Software, die darauf ausgelegt ist, Entscheidungsfindungen zu vereinfachen, indem sie leistungsstarke Data-Science- und fortgeschrittene Analysetechniken nutzt. Snowflake und nun auch Snowpark sind wichtige Bestandteile der Architektur von HyperFinity, und wir sind sehr zufrieden mit der Leistung und Stabilität, die Snowflake der Software bietet, sowie mit den neuen Funktionen, die Snowflake veröffentlicht, um die Arbeit damit noch leistungsfähiger zu machen.
Als Startup hat der Aufbau unserer Anwendung auf Snowflake unsere Infrastruktur und unseren Entwicklungsprozess vereinfacht und den Weg der Software auf den Markt beschleunigt.