Zusammenfassung klinischer Gespräche mit Python
Bei Abridge ist es unsere Mission, jeder medizinischen Unterhaltung Kontext und Verständnis zu verleihen, damit die Menschen ihre Gesundheit im Griff behalten. Wir nutzen wegweisende Forschung im Bereich maschinelles Lernen (ML), um den Menschen zu helfen, sich auf die wichtigsten Details ihrer Gesundheitsgespräche zu konzentrieren. Python treibt wesentliche Aspekte des ML-Lebenszyklus von Abridge an, einschließlich Datenannotation, Forschung und Experimentation sowie die Bereitstellung von ML-Modellen für die Produktion.
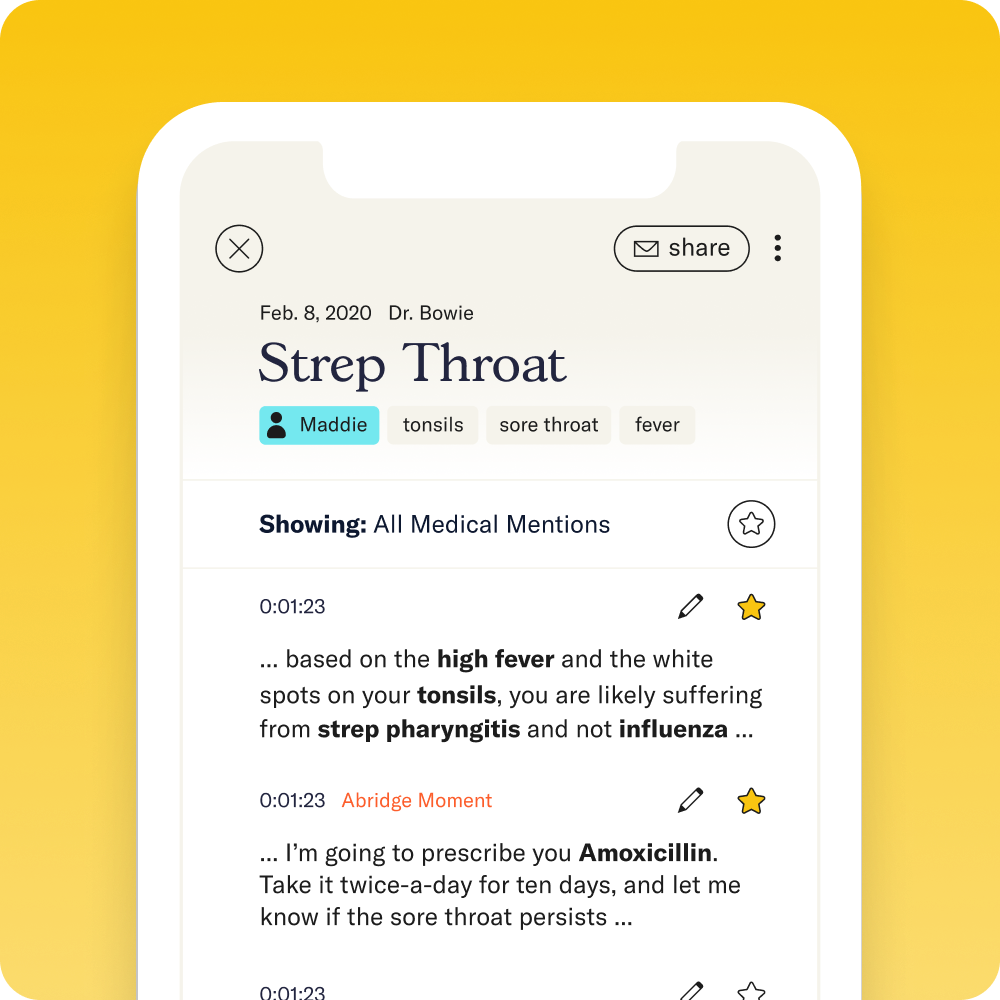
Ein Screenshot unserer mobilen Anwendung, der unser Modul zur Extraktion klinischer Konzepte (als fettgedruckte Wörter) und einen Plan-Klassifikator (als Abridge Moment) zeigt. Beide werden teilweise von Python angetrieben.
Maschinelles Lernen
Dialogmodellierung, Verarbeitung natürlicher Sprache, Informationsextraktion und Zusammenfassung sind einige der aktiven Forschungsbereiche, denen wir uns bei Abridge widmen. Unsere Forschung wird durch einen der größten Korpora echter, anonymisierter und vollständig Einwilligungsbasierter Gesundheitsgespräche ermöglicht. Wir haben die Daten sorgfältig annotiert, unter Verwendung von Richtlinien und Vorlagen, die in Zusammenarbeit mit Klinikern und Forschern entwickelt wurden. Die Python-API von Google Sheets hat es uns ermöglicht, die Erstellung von Annotationsvorlagen zu skalieren, Dateien angemessen an Annotatoren zuzuweisen und den Qualitätskontrollprozess effizient zu verwalten – und das alles, ohne neue Web- oder mobile Anwendungen erstellen zu müssen.
Jupyter Notebook, ein Spin-off-Projekt des IPython-Projekts, ermöglicht es uns, Daten zu bereinigen, Machine-Learning-Modelle zu erstellen und zu trainieren sowie die Leistung von Modellen in einer integrierten Umgebung zu bewerten. Zum Beispiel haben wir Jupyter verwendet, um die Modelle zu erstellen, zu testen und zu visualisieren, die in einigen unserer kürzlich veröffentlichten Arbeiten vorgestellt wurden – darunter eine Pipeline zur Extraktion von Medikamentenregimen, die automatisch Medikamente, Dosierung und Häufigkeit aus medizinischen Gesprächen extrahieren kann, und ein System zur Korrektur von automatischer Spracherkennung (ASR), das die Transkriptionsqualität von generellen ASR-Systemen verbessern kann.
Wir verwenden eine breite Palette von Python-Paketen und -Bibliotheken: Scikit-learn, PyTorch, AllenNLP und Tensorflow für maschinelles Lernen; NLTK und Spacy für die Textverarbeitung; und Numpy, Pandas, Matplotlib, Seaborn für die Datenexploration. Darüber hinaus verwenden wir Django, um Dashboards zum Visualisieren von Daten und zur qualitativen Bewertung unserer ML-Modelle zu erstellen. Alle unsere Produktions-ML-Dienste werden mit den Python-Frameworks Falcon und Gunicorn erstellt. Die Verwendung von Python erleichtert den Übergang von ML-Forschung zu Produktionsdiensten und ermöglicht es uns, unsere Benutzer zuverlässig zu bedienen.
Python ist ein entscheidender Bestandteil des Entwicklungsprozesses bei Abridge. Zusätzlich zu den oben genannten Beispielen verwenden wir Python auch häufig in Verbindung mit mehreren Diensten der Google Cloud Platform (GCP) und zur Einrichtung weiterer Überwachungs- und Debugging-Tools. Wir sind der Python-Community dankbar für die Entwicklung erstaunlicher Werkzeuge, die es uns ermöglichen, bei Abridge magische, patientenzentrierte Erlebnisse zu bieten.
Über die Autoren
Nimshi Venkat ist Machine Learning Researcher und Sandeep Konam ist Mitbegründer/CTO bei Abridge. Wenn Sie sich uns anschließen möchten, besuchen Sie bitte https://www.abridge.com/team